Tutorials · 6 min read
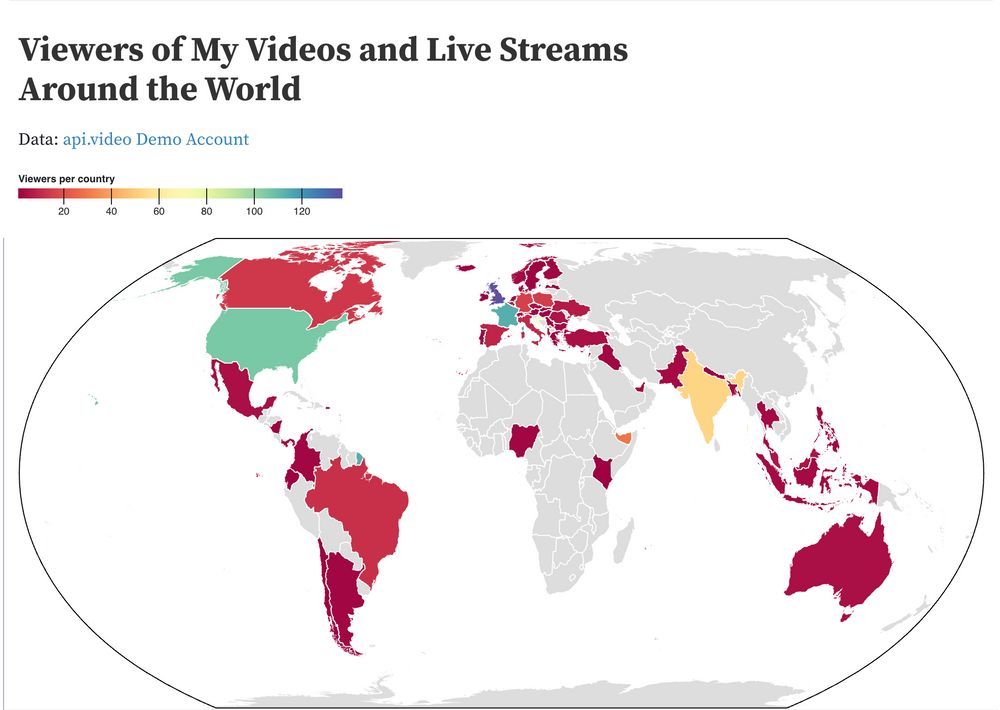
Api.video Analytics: Build a Choropleth Map (and find out what one is)
Build a choropleth showing viewer density by country with Python and Observable!
Erikka Innes
April 8, 2021
python
python
LATEST ARTICLES

Tutorials · 8 min read
What is a webhook and how to use webhooks for real-time video management
Answer critical questions like what are webhooks, how they work, and how you can use them for video management.
api.video · September 12, 2024

Tutorials · 4 min read
How to build AI facial expression detection into your videos with React
Learn how to add AI facial expression detection to your videos using one of Javascript's powerful libraries, React.
Yohann Martzolff · June 26, 2024
Tutorials · 4 min read
How to integrate AI facial expression detection to control your video – Javascript
Learn how to add AI facial expression detection to your videos using Javascript.
Yohann Martzolff · June 25, 2024
Try out more than 80 features for free
Access all the features for as long as you need.
No commitment or credit card required
Video API, simplified
Fully customizable API to manage everything video. From encoding to delivery, in minutes.
Video API, simplified
Fully customizable API to manage everything video. From encoding to delivery, in minutes.
Built for Speed
The fastest video encoding platform. Serve your users globally with 140+ points of presence.
Built for Speed
The fastest video encoding platform. Serve your users globally with 140+ points of presence.
Let end-users upload videos
Finally, an API that allows your end-users to upload videos and start live streams in a few clicks.
Let end-users upload videos
Finally, an API that allows your end-users to upload videos and start live streams in a few clicks.
Affordable
Volume discounts and usage-based pricing to ensure you don’t exceed your budget.
Affordable
Volume discounts and usage-based pricing to ensure you don’t exceed your budget.