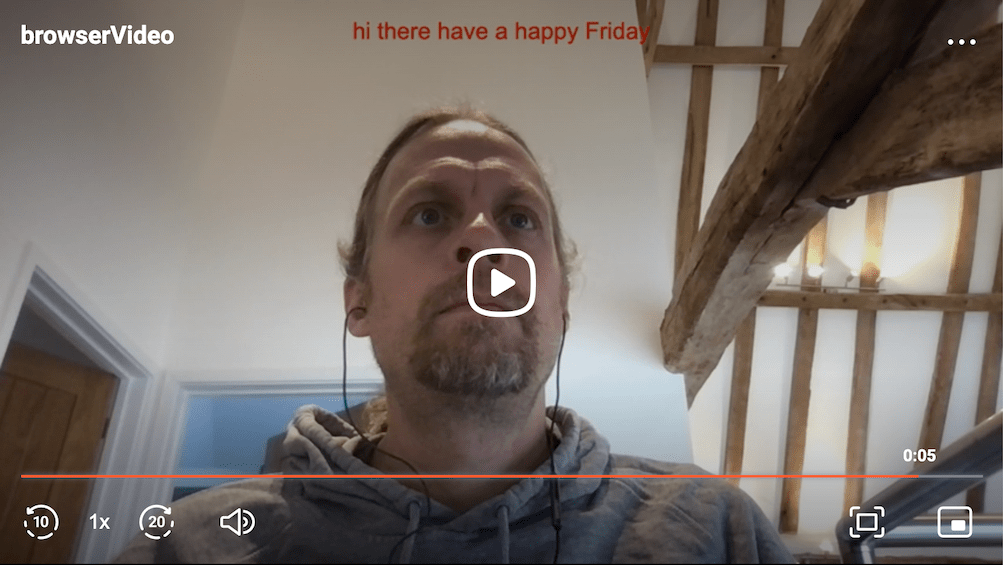
We’ve just released record.a.video, a web application that lets you record and share videos. If that were not enough, you can also livestream. The page works in Chrome, Edge, Firefox, Safari (14 and up), and on Android devices. This means that the application will work for about 75% of people using the web today. That’s not great, but since there are several new(ish) APIs in the application, it also isn’t that bad!
This is part 4 of the continuing series of interesting webAPIs that I used to build the application.
-
In post 1, I talked about the getUserMedia API to record the user's camera and microphone.
-
In post 2, I discussed recording the screen, using the Screen Capture API. I then placed the screen and camera videos on a browser canvas.
-
In post 3 I used the MediaRecorder API to record the video stream pulled from the browser canvas. This stream is then saved and uploaded (for video on demand playback), or streamed to api.video (for live streaming).
-
In this post, I'll discuss the Web Speech API. This API converts audio into text in near real time, allowing to create 'instant' captions for any video being created in the app. This is an experimental API that only works in Chrome, but was so neat, I included it in record.a.video anyway.
Web Speech API
The web speech API is considered experimental, as there the specification is still a draft.
Since it is only a draft, the APIs shown here currently only work in Chrome. Since we want record.a.video to work in all browsers, we need some logic to turn off captions if they are not supported:
if('webkitSpeechRecognition' in window){
console.log("speech recognition supported");
recognition = new webkitSpeechRecognition();
}else{
console.log("speech recognition not supported");
captionRecord = false;
}
console.log("captionRecord", captionRecord);
The captionRecord variable is used to toggle the captioning, so even if the user leaves captions set to on, we remove the caption logic from running here.
SpeechRecognition()
The SpeechRecognition API has 2 sets of results - an interim result (near instantaneous captioning, but not 100% accurate), and a final result (this takes a second, but the results are more accurate,a s more filtering is done on the words, resulting in a better transcription).
In my testing, the interim results were super fast, adn the final results had just a bit too much delay, so I told the API to return the interim results:
recognition.interimResults = true;
I wanted the API to give continuous results - as long as there is talking - I want a transcription:
recognition.continuous = true;
You can set the language of the SpeechRecognition (I did for my testing) before you start the captioning:
recognition.lang = "en-GB";
When you do not set the language, the API will use the language set in the browser, so for internationalisation, not having this set is probably a better move. However, you could also add a setting to allow the user to choose the language to be recognised.
Establishing the speech recognition
Here we set the recognition to start, react to errors and stop.
We also handle all the results (which is set to interim, for the fastest response).
The finalized captions take a second to be created, which is enough time for the user to read the interim captions. So we use the creation of the finalized results as the trigger to clear the interim caption data that has been collected.
recognition.onstart = function() {
recognizing = true;
};
recognition.onerror = function(event) {
console.log ("there was a captioning error");
};
recognition.onend = function() {
console.log ("captioning stopped");
recognizing = false;
};
recognition.onresult = function(event) {
//heres where I'd put where stuff goes in my app....
for (var i = event.resultIndex; i < event.results.length; ++i) {
if (event.results[i].isFinal) {
interim_transcript = "";
} else {
//append the words
interim_transcript = event.results[i][0].transcript;
console.log(interim_transcript);
}
}
};
So the sound from the microphone is fed into the WebSpeech API, and the recognition engine feeds the interim results to the interim_transcript variable.
Printing the caption
We'll draw the text in the interim_transcript variable onto the canvas where the camera and screen are being broadcast to:
function drawCanvas(screenIn, cameraIn,canvas){
var textLength = 60;
canvas.drawImage(screenIn, screenX0,screenY0, screenX1, screenY1);
canvas.drawImage(cameraIn, cameraX0, cameraY0, cameraX1, cameraY1);
//write transcript on the screen
if(interim_transcript.length <textLength){
ctx.fillText(interim_transcript, captionX, captionY);
}
else{
ctx.fillText("no captions", captionX, captionY);
}
setTimeout(drawCanvas, 20,screenIn, cameraIn,canvas);
}
There is code setting the captionX and captionY variables, based on the users' choice of having captions at the top of the screen, or at the bottom.