Today, api.video automates all of its clients and general client documentation. It's fast and convenient for developers to get up and running with the language of their choice. But it wasn't always so easy.
The issue
By the start of 2021, we had 4 SDKs for the api.video API. We had one for each of the following languages:
These SDKs had been built by different developers. They worked pretty well but there were some inconsistencies between them, for example:
- How methods were named
- How the client was instantiated
- What features were included or updated
While we were trying to decide how to handle these inconsistencies, we also decided to meet the demands of our customers by developing two additional SDKs:
We also realized that we wanted to use the correct nomenclature for our clients. While SDK is a popular term, it’s usually misused. A true software development kit is a complete set of tools that facilitates the creation of applications. It’s typically a set of software components that allow you to handle more complex tasks in a particular way out-of-the-box. It can include helper tools for debugging, complete solutions for certain tasks, detailed documentation, different kinds of integration options and more. On the flipside, a client library creates reusable chunks of code you can use as building blocks to do more complex tasks - like the ones you might see in an SDK. We wanted to start using the term clients and made the decision to move to this term rather than SDK.
With that decision settled, we were still faced with maintenance for our growing list of clients. We realized that maintaining all 6 of the clients plus adding more of them and keeping them in sync with our API was going to be really painful. These considerations led us to question the possibility of generating these API clients automatically, instead of maintaining them manually.
The envisaged solution
An API client is a pretty simple thing. It’s mostly composed of models reflecting the API payloads, and methods that make the http calls. All this is pretty well described in the OpenAPI description of our API that we already had for documentation purposes. Therefore, we realized that it shouldn't be too strenuous to generate our API clients using the API description.
After a few investigations on how to achieve this, we chose to use the OpenAPI client generator. The reasons were the following:
- OpenAPI generator is widely used, including in large projects
- It supports a lot of target languages
- It’s open source and highly customizable
Our requirements
Before we got started, we put together our requirements for the new clients. We wanted something that would work well for us and especially our customers. So we came up with this list:
- Ease of use for our customers: Generated clients are often rough and don't handle the small particulars that an API may have. We didn't want the switch to generated clients to make our clients more complicated to use. That means things like authentication, results pagination, efficient upload of huge files using a chunk splitting mechanism, all must be handled seamlessly by the client.
- Release efficiency: One of the goals of having a generated client is to be able to release new versions very quickly. In particular, when a simple change is made to our API (for example adding a new attribute in a payload), we wanted to be able to release a new version of all our API clients the same day.
- Automation: We wanted to avoid manual actions as much as possible between the moment when the API description is updated and when new API clients are released.
The painful part: building the generator templates
For each target language, the OpenAPI generator uses a bundle of templates of the code files that will be generated. If you want to see what it looks like, you can take a look at the base templates for Typescript here: typescript templates. The templating system used is Mustache. Mustache syntax is really simple (sometimes too simple).
For each target language, we started from the base templates included in the OpenAPI generator and we updated them to make them match our needs.
In particular, we had to modify them to:
- Implement our authentication mechanism: the most common authentication mechanisms (OAuth2, basic password) are handled by most of the template bundle, but ours is based on an exchange of a private API key to an access token was not.
- Handle our video upload mechanism: to improve reliability of huge video files transferred we use a mechanism based on file splitting into chunks. This is a particular use case that is of course not handled in the default templates.
- Facilitate the use of the endpoints of our API that return paginated results (it must be easy to retrieve the results of the next page)
- Make some client parameters modifiable by the user, such as: the size of the upload chunks, the API environment to use (sandbox or production), etc.
For some of these adaptations, modifying the templates was not enough, we had to go a little further by modifying the code of the generator itself. It’s pretty straightforward, each target language has a dedicated Java class responsible for generating the variables sent to the template engine from the API description. We simply had to write subclasses of these Java classes and put the needed changes in them.
The release process before automation
Once the template has been written, generating the code of a client is done by executing a single Maven command. In the weeks following the end of the development of our generator, the process of releasing new versions of the clients after an API change was very manual. It looked like this:
- The API description was updated to reflect the change made in the API
- Someone from the Ecosystem tech team launched the generator 6 times on their computer (1 execution per client)
- For each generated client, the teammate ran the unit tests & integration tests
- If everything went well, they committed the new code of each client to its dedicated GitHub repository (6 commits)
- They created a GitHub release on each of the 6 repos
- They manually released a new package on each package repository (npm.js for javascript, maven for java, pypi for python, etc.)
That was really painful and error-prone, so we decided to automate all of this.
The release process with automation
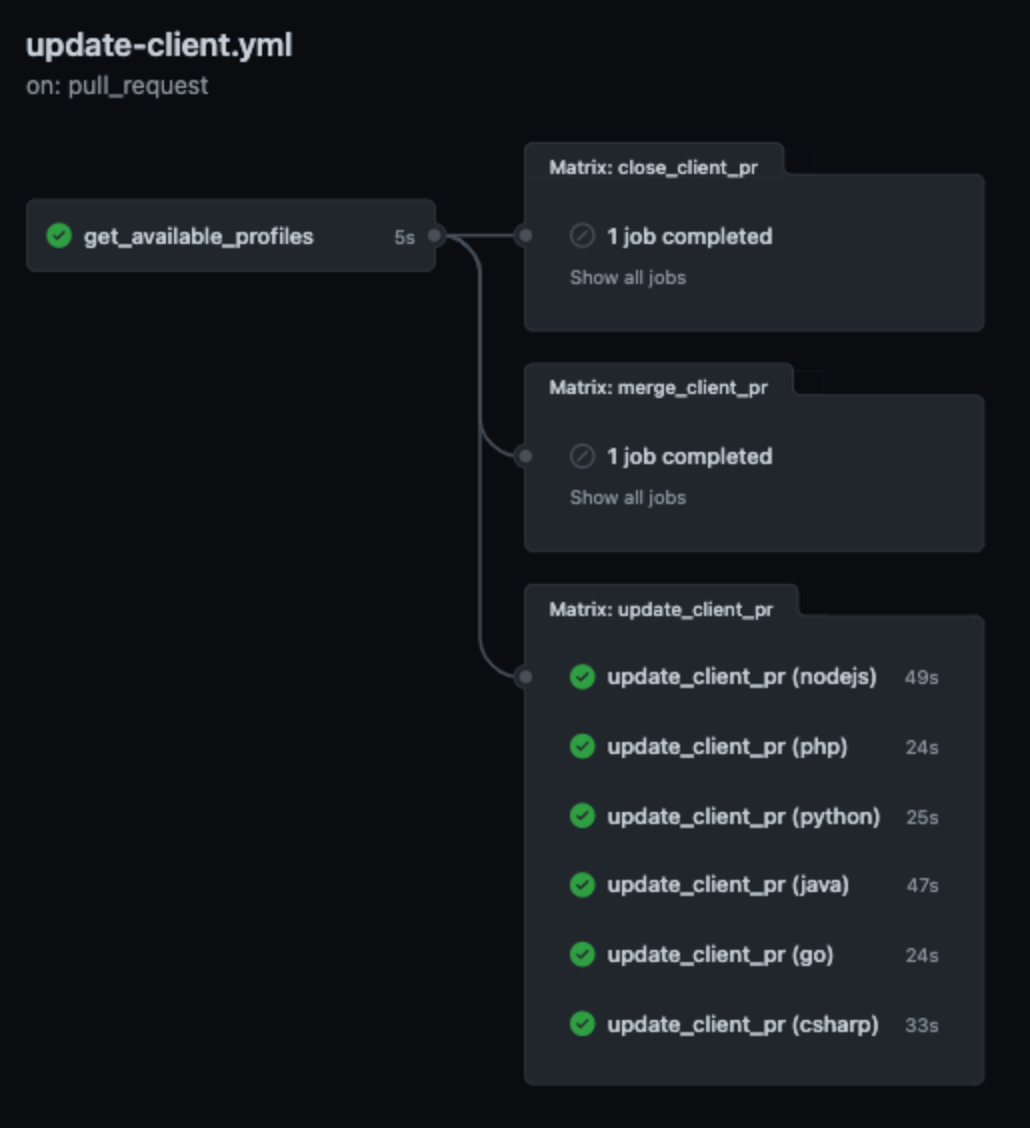
In total we have 7 GitHub repositories for our client : 1 for the generator itself, and one per generated client.
Thanks to GitHub Actions, we have implemented the following process:
When a pull request is made on the generator repository (this happens when the API description itself is updated, or when templates are changed), 6 GitHub actions are triggered on the generator repository: one per client. Each of them will:
- clone the code of the client from its repository
- launch the Maven command to generate a new version of the client
- if something changed in the code of the client a branch is created on the client repository, a commit is made, and a PR is created